Send Again After Getting Bs Request
https://gds.blog.gov.uk/2020/04/03/how-gov-uk-notify-reliably-sends-text-letters-to-users/

GOV.Britain Notify lets central government, local authorities and the NHS transport emails, text messages and letters to their users.
Nosotros usually send between 100,000 and 200,000 text messages a day . It'due south of import for services using Notify that they're able to chop-chop and successfully send text messages to their users.
Those services rely on us to send important messages , for example a flood warning or a two-factor authentication (2FA) code so their users can sign in to some other service. We design and build Notify with this in mind.
Using multiple text message providers
When a primal government, local authority or NHS service wants to send a text message to a user, they enquire Notify, either manually through our spider web interface or using our API , to send it. We and so ship an HTTP request to a text message provider to ask them to deliver the message. No provider will exist working perfectly 100% of the time ( nor should nosotros expect them to exist ). Because of this we have 2 dissimilar providers, so if one encounters any issues we tin use the other provider to send the message.
Our original load balancing design
Originally we sent all text messages through ane provider, say provider A. If provider A started having trouble, Notify would automatically swap all traffic to provider B – a process known as a failover. We used 2 measures to decide if a provider was having problems and failover. We measured a:
- single 500-599 HTTP response code from the provider
- slowdown in successful commitment callbacks (a bulletin back from the provider to say information technology had delivered the message to the recipient)
To make up one's mind if callbacks were slow, we'd mensurate the final x minutes of letters existence sent. Nosotros'd consider callbacks slow if 30% of them took longer than 4 minutes to report back as delivered.
Nosotros could also manually swap traffic from, say, provider A to provider B as nosotros wanted. Nosotros did this often, maybe once a week, to effort and accomplish a roughly 50/50 split of letters sent between each of our providers. If we concluded up sending only a modest number of letters through 1 provider over the long run, they might non be massively incentivised to be a provider in the time to come.
A problem with our original design
One day, towards the end of 2019, we had a large spike in requests to send text messages. We sent all these requests to 1 of our providers simply information technology turned out they couldn't handle the load and started to fail. Our system swapped to the other provider simply it turned out that sending a large corporeality of traffic out of nowhere caused them to start returning errors besides. It was likely that our providers needed time to scale upwards to handle the sudden load we were sending them.
How we improved our resiliency
We changed Notify to ship traffic to both providers with a roughly l/50 divide. When a single text bulletin is sent, Notify volition pick a provider at random. This should reduce the gamble of giving our providers a very large corporeality of unexpected traffic that they volition not exist able to handle.
We besides changed how we handled errors from our providers. If a provider gives us a 500-599 HTTP response lawmaking, nosotros would reduce their share of the load past 10 pct points (and therefore increase the other provider by x percentage points). We will not reduce the share if it's already been reduced in the terminal minute.
We likewise decided that if a provider is slow to evangelize letters, measured in the same way as before, we would reduce their share of the load by x percentage points. Once more, we will non reduce the share if information technology's already been reduced in the last minute.
Information technology's important that we wait a infinitesimal before assuasive another 500-599 HTTP response code to decrease that provider'southward share of traffic over again. This ways that simply a modest bleep, for example v 500-599 HTTP responses over a second, doesn't switch all traffic to the other provider too quickly.
As balancing our traffic
We still had the manual job of equally balancing our traffic if we no longer needed to push that traffic towards one of the providers. We decided that, if neither provider had changed its balance of traffic in the last hour, we'd move both providers 10 percentage points closer to their defined resting points.
This means our system will automatically restore itself to the center and removes the manual burden of our squad trying to send roughly equal traffic to both providers. We tin still manually determine what pct of traffic goes to each provider if we want to, but this is something we anticipate doing rarely.
We did consider trying to overcorrect traffic to bring the overall balance back to 50/fifty over, say, a month. For example, if provider A has an incident and receives no traffic for 24 hours, we could give it 70% of the traffic for the next few days to overcorrect the traffic information technology lost. We decided doing this would but bring a small benefit and would increase the complication of our load balancing system. Keeping things as unproblematic as possible won the argument in this case.
How the service is doing now
The following graphs bear witness the number of text messages we sent to each of our providers per 2nd.
On the morning of 26 Jan i of our providers ran into bug and we reduced their share of traffic downward to cipher. Every hr for a while afterwards this you can encounter us requite them x% of traffic to see if they accept recovered enough, but they hadn't then it got reduced back to 0% again.
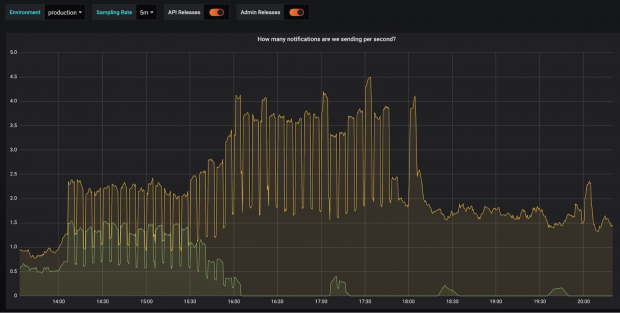
Finally the side by side afternoon their organisation improved and we moved back towards a roughly equal split of traffic.
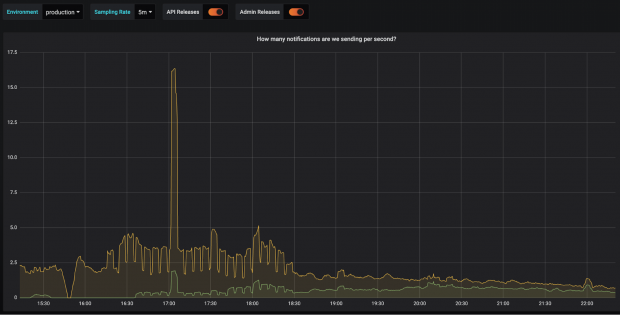
What's next
This gear up works for u.s.a. now. As we proceed to grow we'll do more stuff like this to make sure we're providing the best operation, resilience and value for money to Notify'due south users.
Visit GOV.United kingdom Notify for more than data and to create yourself an account.
Source: https://gds.blog.gov.uk/2020/04/03/how-gov-uk-notify-reliably-sends-text-messages-to-users/
0 Response to "Send Again After Getting Bs Request"
Post a Comment